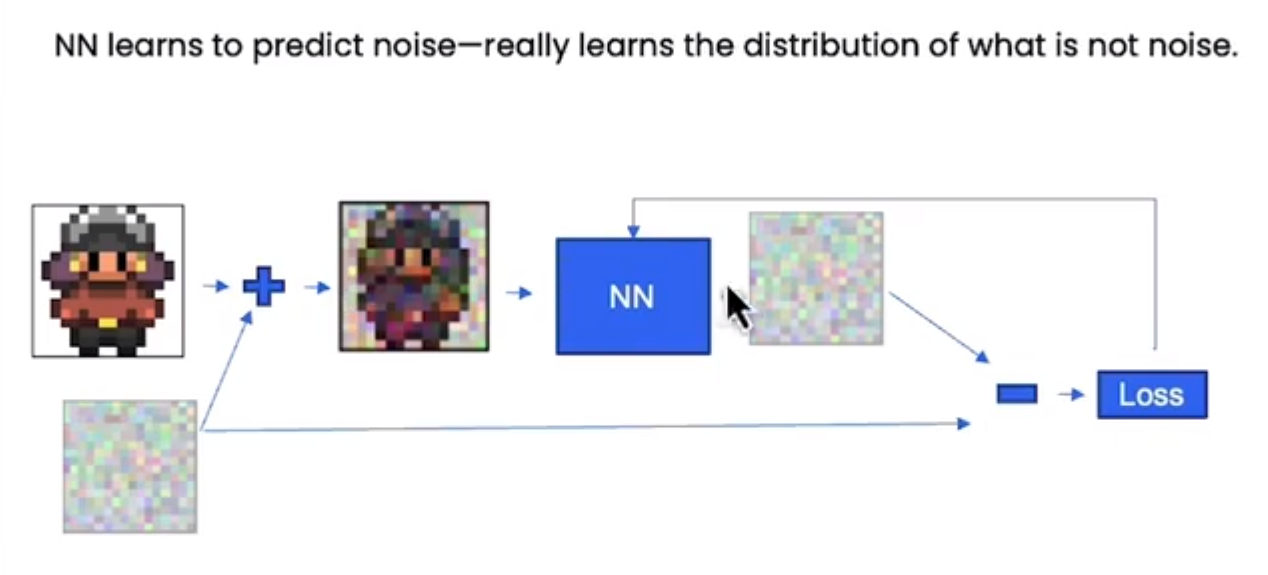
You Want a neural network to learn what a sprite is: fine details general outlines everything in between add different noise levels to the training data of sprites, to emphasi…
相同点: 机制:两者都使用了点积注意力机制(scaled dot-product attention)来计算注意力权重。 参数:无论是自注意力还是交叉注意力,它们都有查询(Query)、键(Key)和值(Value)的概念。 计算:两者都使用查询和键之间的点积,然后应用softmax函数来计算注意力权重。 输出:在计算完注意力权重后,两者都将这些权…
https://arxiv.org/pdf/2304.06720.pdf https://rich-text-to-image.github.io/ Demostration Motivation 问题:如何使用rich text? 先前的解决方案:直接将rich-text翻译为更长的plain text → 生成图片效果很差 Method 我们的…